
Por Ram Kumar, Akshay Hatewar y Vaidehi Soman
Grupo de ciencia y tecnología de fabricación, Cipla
Las compañías farmacéuticas realizan pruebas rigurosas para medir los atributos críticos de calidad de los medicamentos que producen. Cuando se descubre un problema con un lote en particular, los equipos de fabricación deben identificar la causa raíz lo antes posible para evitar demoras en la entrega y escasez de medicamentos críticos.
El análisis de causa preciso y oportuno es un desafío debido a la amplia variedad de materias primas, máquinas y múltiples pasos de procesos involucrados en la fabricación farmacéutica. En el pasado, los equipos ingresaban manualmente los datos de las etiquetas de las materias primas y las impresiones de las máquinas en hojas de cálculo para su análisis, pero este método era lento y propenso a errores. Además, no había ninguna herramienta ni metodología para analizar este enorme conjunto de datos de una sola vez.
En Cipla, ahora usamos una aplicación web para análisis de procesos avanzados. La aplicación, integrada en MATLAB ®, automatiza la recopilación de datos, los analiza mediante modelos de aprendizaje automático y muestra los resultados. Con esta aplicación, lo que antes nos tomaba varias semanas para identificar las causas, ahora toma un par de días. Además, podemos predecir problemas potenciales con lotes específicos y tomar medidas correctivas de inmediato en lugar de esperar hasta 14 días para obtener los resultados de las pruebas de control de calidad en el producto terminado.
La aplicación web Cipla integrada en MATLAB muestra los resultados del análisis de fabricación farmacéutica de grandes cantidades de datos utilizando modelos de aprendizaje automático.

Figura 1. Cipla realiza análisis de fabricación farmacéutica con una aplicación integrada en MATLAB.
Recopilación y preprocesamiento de datos
Los datos que los equipos de fabricación farmacéutica necesitan analizar son muy heterogéneos y provienen de fuentes dispares, pero se pueden agrupar en dos grandes categorías: atributos críticos de materiales (CMA) y parámetros críticos de proceso (CPP). Los CMA incluyen propiedades de las materias primas utilizadas en la fabricación, como la densidad del material y la distribución del tamaño de las partículas, así como su proveedor, edad y vida útil. Un producto típico se compone de unas 20 materias primas, cada una con más de una docena de CMA. Los CPP incluyen mediciones de series de tiempo capturadas durante las operaciones de unidades múltiples en el proceso de fabricación. Por ejemplo, una operación de una sola unidad, como la granulación en lecho fluidizado, puede tardar de 2 a 3 horas o más en completarse. Durante este tiempo, los parámetros del proceso como la temperatura, la humedad, y la velocidad del aire que se mueve a través de la máquina y el diferencial de presión a través de los filtros se registran cada minuto. Otra operación unitaria, como la liofilización o la liofilización, suele tardar 48 horas o más en completarse.
Acudimos a MathWorks Consulting para desarrollar una aplicación para recopilar y estructurar estos datos. Utilizamos Database Toolbox™ para recuperar CMA y procesar lotes de datos desde un almacén de datos de Microsoft® Azure® y otras bases de datos. Con Industrial Communication Toolbox™, pudimos acceder a datos CPP adicionales directamente desde los servidores OPC en nuestras instalaciones. La aplicación Database Explorer fue particularmente útil para conectarse a varias bases de datos de Cipla y explorar visualmente los datos.
Los datos de CMA a los que accedimos estaban relativamente limpios y requerían poco procesamiento previo. Los datos de CPP, en particular las mediciones de presión diferencial eran mucho más ruidosos. Aplicamos filtros de Signal Processing Toolbox™ para reducir el ruido y revelar tendencias en los datos.
Construcción de modelos de aprendizaje automático
Una vez que tuvimos una representación bien estructurada de los datos de CMA y CPP, nuestra siguiente tarea fue construir modelos de aprendizaje automático. Estos modelos nos permitirían determinar cuál de los cientos de propiedades del material y parámetros del proceso tuvo el mayor efecto sobre un atributo en particular. Matemáticamente hablando, hay una función y= f(X1,X2, … ,Xnorte) dónde y es el atributo crítico de calidad y cada X representa una variable CMA o CPP. Necesitábamos nuestros modelos para determinar en qué medida cada X influencias y.
Implementamos un algoritmo que aplica tres técnicas de aprendizaje automático en una serie: análisis de componentes principales (PCA), mínimos cuadrados parciales (PLS) y bosque aleatorio. El espacio x (gráfico PCA) revela que los lotes tienen diferencias en las propiedades de la materia prima y/o han sido procesados de manera diferente (Figura 2). Además, los lotes dentro y fuera del objetivo se han procesado de varias formas, pero siempre han dado como resultado un producto fuera del objetivo. Confirmamos esto usando el espacio xy (gráfico PLS). En este diagrama de espacio xy, todos los grupos fuera del objetivo se unen para formar una gran zona fuera del objetivo. Aplicamos un bosque aleatorio sobre el PLS para comprender con qué precisión el modelo clasifica el lote como dentro del objetivo versus fuera del objetivo.
Diagrama de trazado de Cipla que muestra los resultados de aplicar análisis de componentes principales y modelos de aprendizaje automático de mínimos cuadrados parciales para determinar los efectos de diferentes propiedades y parámetros de proceso en un atributo.

Figura 2. Resultados de PCA (izquierda) y PLS (derecha). Los círculos verdes son los lotes correctos; los cuadrados rojos son los lotes fuera del objetivo.
Optamos por el aprendizaje automático en lugar del aprendizaje profundo para poder cumplir con un requisito clave de nuestro análisis: la interpretabilidad. Necesitamos comprender completamente cualquier problema de fabricación que identifiquemos para abordarlo de manera integral y evitarlo en el futuro. El aprendizaje automático tradicional permite este nivel de comprensión, mientras que el aprendizaje profundo generalmente no lo hace.
Empaquetado e implementación de una aplicación web
Uno de nuestros objetivos clave era la democratización de la analítica: queríamos desarrollar una solución que pudiera ser utilizada en Cipla por muchos usuarios, no solo por un pequeño grupo de expertos. Para cumplir con este objetivo, creamos una interfaz simple con App Designer . Lo empaquetamos con los algoritmos de aprendizaje automático y lo implementamos como una aplicación web con MATLAB Web App Server™.
Al trabajar con la aplicación, los usuarios comienzan seleccionando el producto que desean analizar. La aplicación recupera los datos de CMA relevantes para ese producto específico y crea los modelos PCA, PLS y de bosque aleatorio. La aplicación muestra los resultados de los modelos, incluida la contribución relativa de cada variable al atributo de calidad crítico, y destaca los factores importantes (Figura 3). Después de revisar los resultados, el usuario puede decidir construir un modelo reducido con estos factores resaltados para mejorar la precisión del modelo. Por ejemplo, si la iteración inicial incluía 500 variables, pero se muestra que un subconjunto de 300 variables tiene poco efecto en los resultados, entonces el usuario puede simplificar el modelo omitiendo ese subconjunto y volver a ejecutar el análisis.
Una interfaz de usuario integrada en App Designer muestra los resultados de aplicar modelos PCA, PLS y de bosque aleatorio a los datos de CMA.
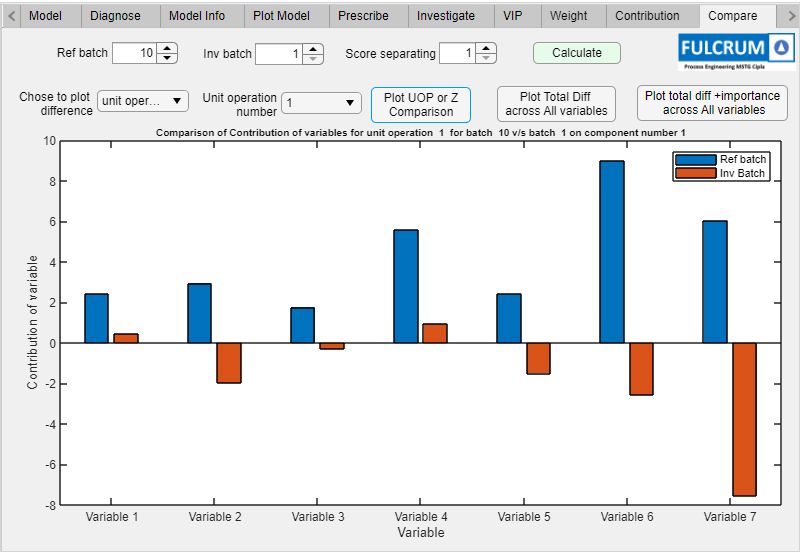
Figura 3. Resultados de los modelos de datos de CMA, incluida la contribución relativa de cada variable.
Prueba piloto de una versión en tiempo real de la aplicación
Nuestro equipo está desarrollando actualmente una versión en tiempo real de la aplicación que se pondrá a prueba este año. Esta versión capturará los datos del servidor OPC de las operaciones de la unidad en tiempo real, los introducirá en los modelos de aprendizaje automático y determinará si los procesos están operando dentro de los parámetros de control establecidos.
¿Por qué MATLAB?
Antes de decidir utilizar MATLAB para nuestro análisis de fabricación, consideramos varias alternativas. Una opción que evaluamos fue un paquete de software comercial. El software era costoso, en parte porque estaba hecho a medida para la industria farmacéutica y no podíamos personalizarlo completamente para satisfacer nuestras necesidades.
Otra opción era desarrollar nuestra propia solución utilizando bibliotecas de código abierto en Python ® o un lenguaje similar. Esta opción no era factible porque necesitábamos estar seguros de que los algoritmos que usamos para crear nuestra aplicación se habían validado y probado exhaustivamente. También necesitábamos soporte técnico para acceder a los datos de un conjunto diverso de almacenes de datos. Con MATLAB y el soporte de MathWorks Consulting Services, pudimos crear una aplicación de bajo costo totalmente personalizada y compartirla en toda la empresa.
Ir al artículo original
Traducción: Jacqueline Vicarte
Más información sobre este producto
Entre en contacto con: Jacqueline Vicarte
jvicarte@multion.com